
本文由显卡大神Edison Chen撰写,首发于知乎,授权本站转载。

在 8 月 11 日,NVIDIA 在官方网站发布了一个 21 天的倒数页面,预告在 21 天后将会有一个 GeForce 系列的特别发布活动,随着时间的临近,官方不断地发布了过去 21 年来推出的一系列产品和技术。
例如 1999 年推出的第一代 GPU 产品 GeForce 256,2001 年第一款可编程着色器 GPU 产品 GeForce 3 Ti,2003 年第一款尝试进入 CG 制作领域的 GPU 产品 GeForce FX,2004 年王者归来的 GPU 产品 GeForce 6800 Ultra,2006 年开创 CUDA 和统一着色器纪元的 GPU 产品 GeForce 8800 系列,2010 年吹响 GPU 进军超算市场号角的 GeForce GTX 400 系列,以及两年前推出的首个集成硬件光线追踪内核(RT Core)的 GeForce RTX 系列。
这其中的发展或许有点波折,例如 GeForce FX 系列,但是总的来说,NVIDIA 勇于创新的产品发展方向被证明是正确的,特别是 GPU、CUDA、RT Core 等新技术的引入,都获得了游戏玩家和业界的高度认可。
对游戏来说,图灵架构引入的硬件光线追踪加速可以认为是有电脑游戏以来最大的图形革命,甚至说是唯一的一场革命也不为过,它彻底改变了以往游戏画面基本依赖光 栅化的渲染方式,让人们首次在个人电脑里可以体验光线追踪游戏大作。
不仅游戏玩家获益,图灵在内容创作上的影响更大,许多离线渲染器都纷纷转投图灵,现在主流渲染器都已实现硬件光线追踪加速。牙膏厂 Intel 也都着急了,眼看这样下去 CPU 市场要大受影响了,最近也密集宣传明年自己要出独立 GPU 了。
在倒数结束后,老黄家再次现身自家厨房发布会现场,拿出来的自然是大家期盼已久的安培架构游戏卡 RTX 3000 系列。
面向玩家和内容创作的 RTX 3000 系列
GeForce RTX 3000 系列第一波产品有三款,分别是基于 GA102 GPU 的 GeForce RTX 3090、GeForce RTX 3080 以及基于 GA104 的 GeForce RTX 3070。GA102 和 GA104 代号中的 A 就是指安培 Ampere,其中 GA102 采用三星 8N(专门为 NVIDIA 定制的 8 纳米)制程,芯片面积 628 平方毫米(TU102 是 754 平方毫米),晶体管数量高达 280 亿(TU102 是 186 亿),是下一代游戏机 XSX SoC (CPU + GPU)的 1.83 倍。
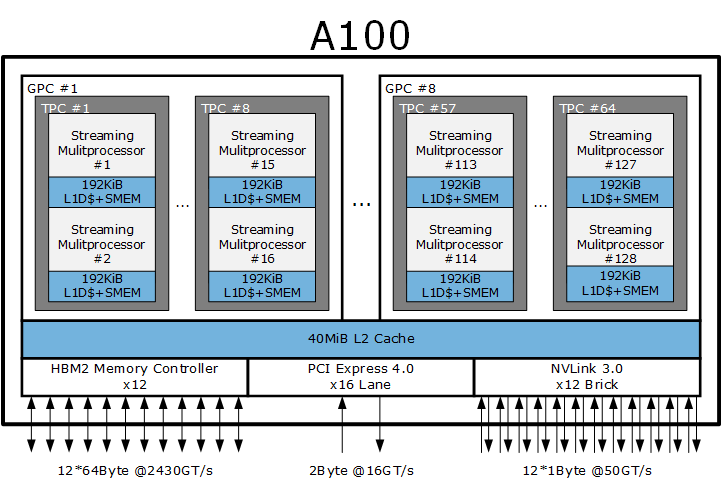
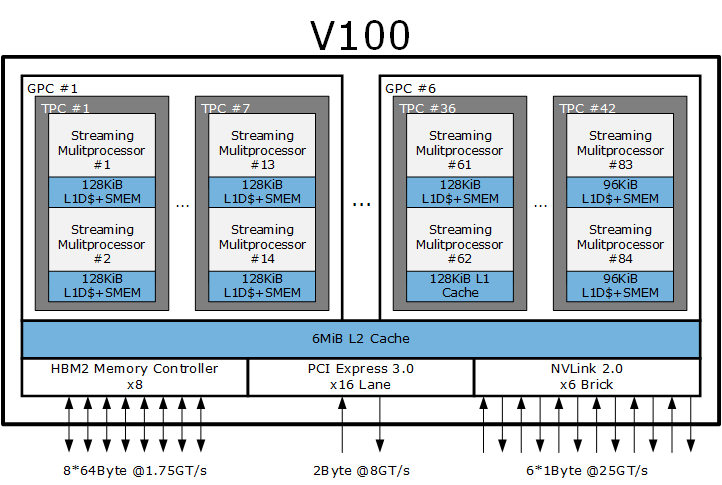
安培架构的最大芯片是更早之前发布的 A100,基于台积电 7 纳米制程的 A100 完全针对超算和深度学习设计,去掉了显示输出模块和光线追踪内核,具备极强的双精度性能,拥有一些特别的计算加速模块,例如硬件 JPG 编解码器、12 通道的 NVLINK 3.0 总线、庞大的 40 MiB L2 Cache 等,晶体管数量高达 540 亿,价格和成本极高,一般只有一定规模的企业才有条件选择,与日常游戏娱乐无缘。
对游戏玩家和创作者而言,GeForce RTX 3000 才是真正专门定制的产品,接下来说的也主要围绕这个系列的产品展开。
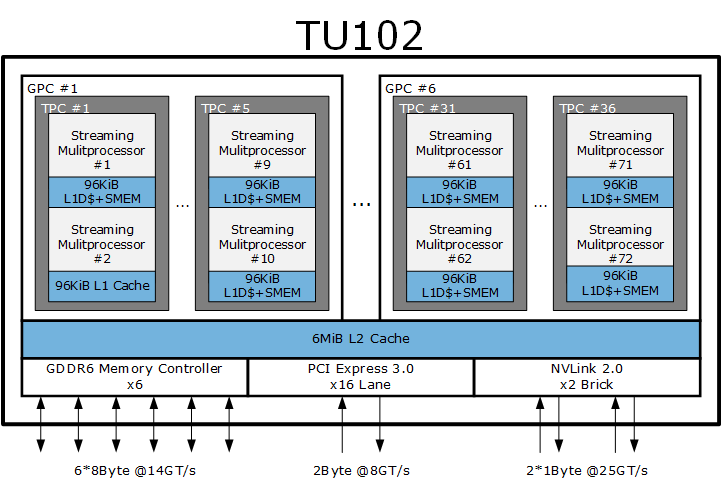
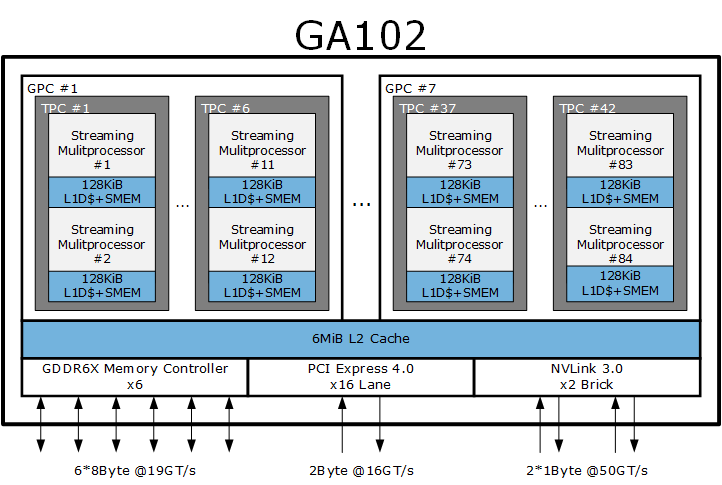
与 A100 纯粹作为超算加速器设计不同的是,GA102、GA104 具备完整的显示输出模块、更高的单精度计算性能、光线追踪内核,更偏向于游戏和日常应用加速,其 CUDA compute capability 版本是 8.6(这部分的更多细节你可以在关于缓存子系统看到)。
和上一代的图灵架构相比,基于 GA102 的 GeForce RTX 3080 比价格同为 699 美元的 GeForce RTX 2080 Super 在单精度性能上提高了接近两倍,光线追踪性能前者是后者的 1.7 倍,面向人工智能的张量计算性能可以达到两倍。
GA102 和 GA104 均采用三星的 8 纳米制程生产,RTX 3090(GA102)、RTX 3080(GA102)、RTX 3070(GA104)的全卡功耗分别为 350 瓦、320 瓦、220 瓦,国行报价分别为 11990 元、5499 元、3899 元,价位基本上对应上一代的 RTX 2080 Ti、RTX 2080 Super、RTX 2070。
本文主要是偏架构向,因此具体的产品细节例如散热设计我们不打算过多介绍,接下来我们首先从 SM 开始介绍安培架构。
架构变化——SM 浮点性能加倍
众所周知,NVIDIA CUDA 是一个多层次的线程架构,对程序员而言,CUDA Core 是其直接编程的处理单元,CUDA Core 的局部资源由名为 Streaming Multiprocessor 或者简称 SM 的单元包围着。
如果按照 CPU 这边的微架构术语,CUDA Core 是 SIMD 单元中的一个运算单元,而 SM 因为具备自己的程序计数器所以可以视作和传统 CPU 内核对等的内核。可以说,一名 CUDA 程序员,首先要掌握的最基本知识就是如何使用将各个 SM 的资源有效地分配给 CUDA Core 使用。
CUDA 开发人员了解 SM 和 CUDA Core 的关系后,就可以写很多有用的代码了,不过对于游戏来说,这显然并不够。游戏开发涉及大量的硬件图形加速单元,例如光栅器、纹理取样等,为此,NVIDIA 或者其他厂商的 GPU 还按照光栅器和纹理单元做更进一步划分。
在游戏图形处理单元术语中,NVIDIA 这边还有 GPC 和 TPC 两种概念,所谓 GPC(Graphics Processing Clusters)就是指有能力独立绘制一个三角形的处理器簇,而 TPC (Texture Processing Clusters)则是纹理处理簇,负责纹理处理。
面向游戏的顶级安培游戏架构 GPU GA102 包含有 7 个 GPC,42 个 TPC,84 个 SM。
NVIDIA GeForce RTX 3080 和 NVIDIA GeForce RTX 3090 的 GA102 并非足本,前者的屏蔽了一个 GPC,TPC 数量是 34 个,SM 数量是 68 个,最高频率 1710MHz。
而后者的 GPC 是 7 个,TPC 数量是 41 个,SM 数量是 82 个,最高频率 1.7GHz。
按照规模屏蔽单元的设计主要是出于成本考虑,因为只需要设计一枚芯片,就能满足多个价位的需求。
安培的 SM 和之前的图灵类似,每个 SM 里面包含了四个 warp 指令调度器,每个 warp 指令调度器对应一个 16 路 SIMD(或者按照 NVIDIA 的说法是 SIMT)的 Sub-Core(子内核),一共 4 个 S-ub-Core,每个 SM 还配有一个 RT Core(光线追踪内核)。
安培的 Sub-Core 和 RT Core 都做了架构增强。
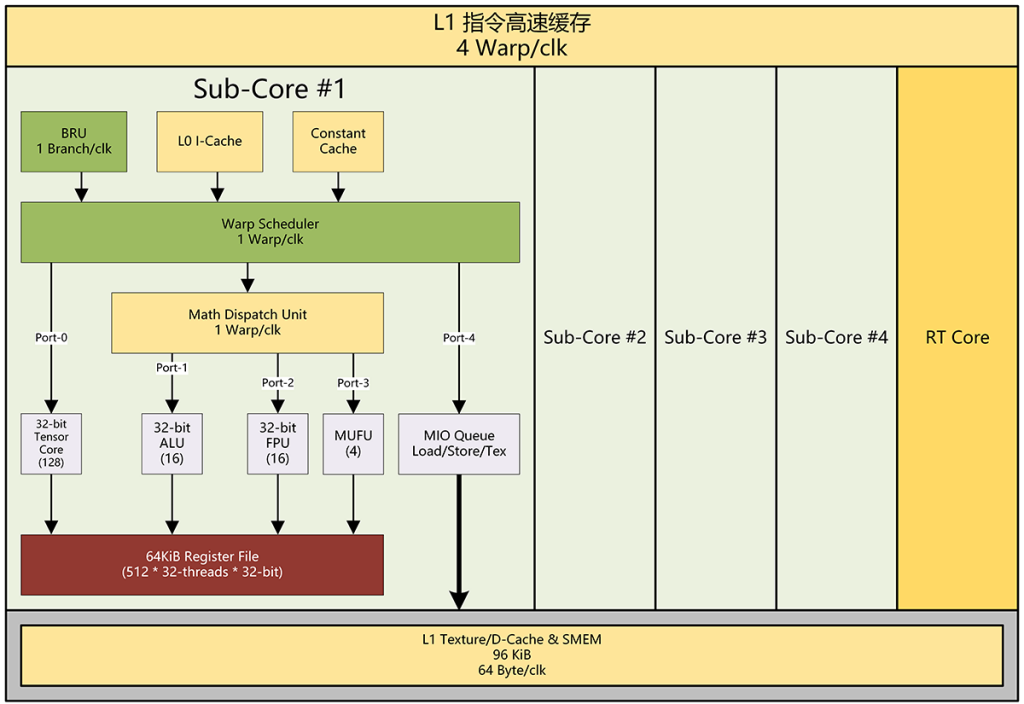
在图灵里,每个 Sub-Core 都有 5 个指令发射端口:
- Port-0:对应 Tensor Core
- Port-1:对应 SIMT-16 INT32 单元
- Port-2:对应 SIMT-16 FP32 单元
- Port-3:对应 SIMT-4 MUFU 单元
- Port-4:对应 Load/Store 单元
在 CUDA 编程框架术语中,SIMT-16 里的每个处理元(Processor Element,简称 PE,OpenCL 术语)被称作 CUDA Core,因此每个 SIMT-16 里包含了 16 个 CUDA Core。
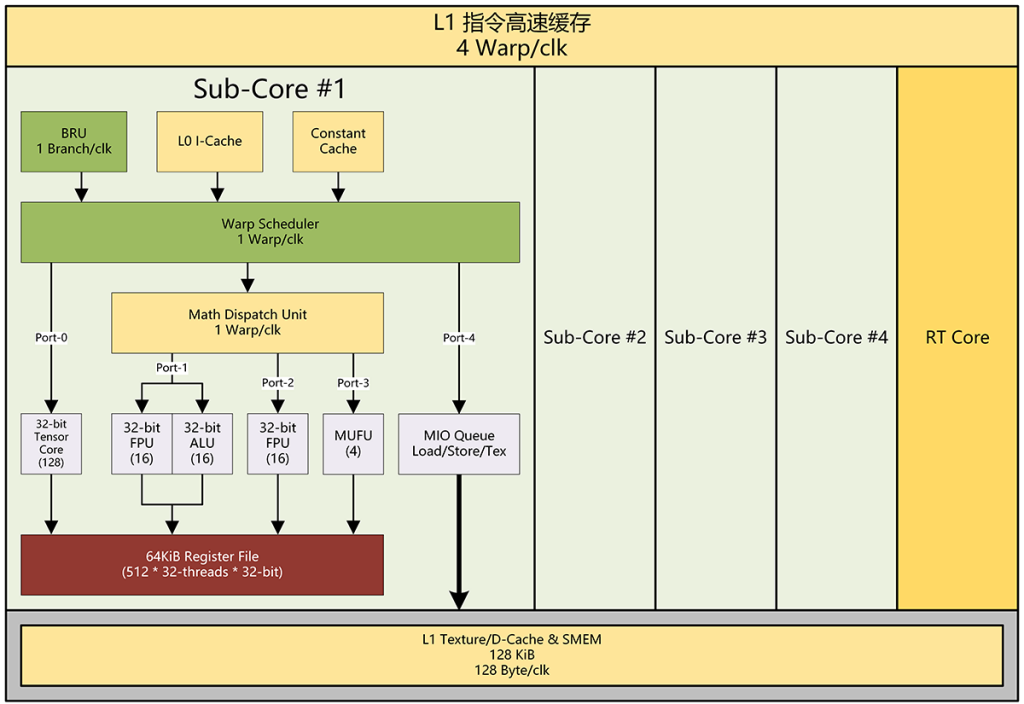
在安培架构中,每个 Sub-Core 依然只有 5 个指令发射端口,但是其中一个 SIMT-16 发射端口可以发射 INT32 或者 FP32 两种指令:
- Port-0:对应 Tensor Core
- Port-1:对应 SIMT-16 INT32 或 SIMT-16 FP32 单元
- Port-2:对应 SIMT-16 FP32 单元
- Port-3:对应 SIMT-4 MUFU 单元
- Port-4:对应 Load/Store 单元
经过这个调整后,现在安培的每个 SM 在同一个周期里可以以 1:1 或者 2:0 的比例运行浮点和整数指令,在 2:0 模式下,那就是每个 SM 一个周期跑 128 条浮点 FMA 指令或者说 256 个浮点操作。
而在 1:1 模式下则和以前的图灵一样,可以跑 64 条浮点指令加 64 条整数指令,也就是 128 个浮点操作加 128 个整数操作。
图灵架构当初引入并行的 INT32 目的是因为现在游戏里整数指令比例不低,依照当时提供的资料,是平均每 100 条浮点指令就有大约 36 条整数指令,这个比例大概是 2.77:1(见下图):
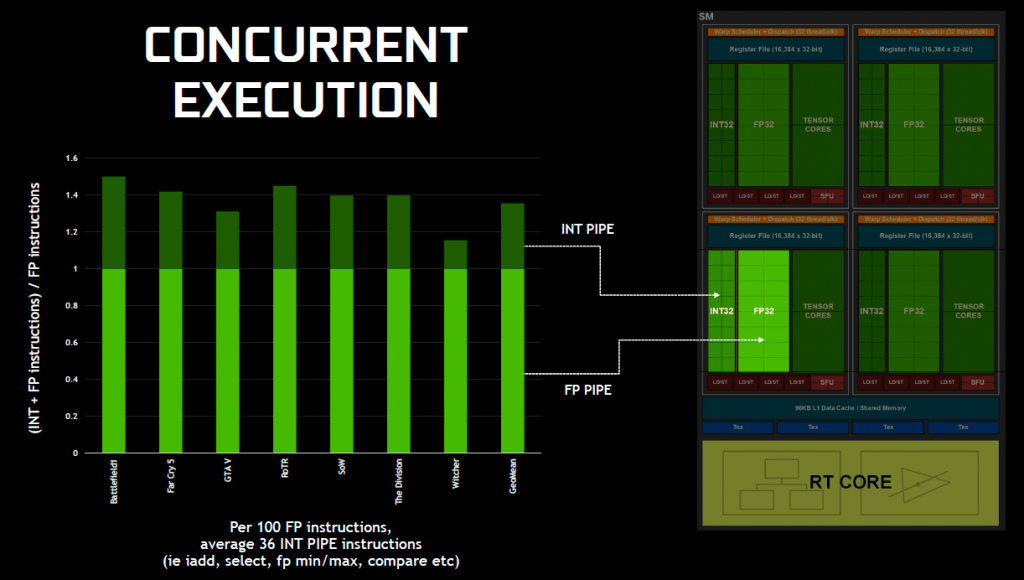
所以,安培架构的 SM 做出上述调整同样是性能上的选择,使得运算资源更接近于实际的比例。
这里可能会一些争议。因为 NVIDIA 公布的 CUDA Core 数量是基于 FP32 单元数统计的,所以有些人会觉得有些别扭,Port-1 和 Port-2 的计算资源是不一样的。
其实这点我觉得如何命名还是得看官方的意思,我们了解中间的含义就行。而且,如果把 Port-1 和 Port-2 做成图灵那样对等的话,增加的额外晶体管所能带来的好处可能抵消不了增加的耗电、制造成本。
目前的设计显然是 NVIDIA 经过仔细对比后确定的最佳化实现。
现在,让我们拿出计算器,看看经过这番调整后,GeForce RTX 3080 的理论性能可以达到怎样的水平。
256 FP Ops per SM * 68 SM * 1710 MHz = 17408 FP Ops * 1710 MHz = 29767680 MFLOPS = 29.8 TFLOS
而上一代图灵架构的 GeForce RTX 2800 Super 是:
128 FP Ops per SM * 48 SM * 1815 MHz = 6144 FP Ops * 1815 MHz = 11151360 MFLOPS = 11.2 TFLOS
简而言之,就是新的 RTX 3080 在浮点性能上几乎达到 RTX 2080 Super 的 2.7 倍。
RTX 3080 和 2080 的全卡功耗分别是 320 瓦和 250 瓦,因此两者的纸面浮点性能耗电比分别是 93 GFLOPS 每瓦和 45 GFLOPS 每瓦,前者是后者的两倍多一点。
架构变化——关于片上存储以及 ROP
和图灵架构一样,安培架构的 SM 采用了一体化的缓存子系统,L1 纹理缓存、L1 数据缓存和 Shared Memory 都位于同一块静态缓存中,大小为 128 KiB。
关于 Shared Memory,Shared Memory 是 CUDA 架构中允许同一个线程块实现近程交换的内存,是离 CUDA Core 最近的存储器,速度非常快,最初的设计速度和寄存器堆差不多,是 CUDA 编程中最宝贵的存储资源。
在通用计算模式下,GA10X SM 的可以按照如下配置进行分区:
- 128 KiB L1D + 0 KiB Shared Memory
- 120 KiB L1D + 8 KiB Shared Memory
- 112 KiB L1D + 16 KiB Shared Memory
- 96 KiB L1D + 32 KiB Shared Memory
- 64 KiB L1D + 64 KiB Shared Memory
- 28 KiB L1D + 100 KiB Shared Memory
在图形和异步计算模式下,GA10X SM 的可以按照如下配置进行分区:
- 64 KB L1D/Texture + 48 KiB Shared Memory + 16 KiB GFX Cache
可以看到,GA10X 架构的缓存子系统拥有比图灵架构灵活得多的 L1 缓存分区方式,特别是图形和异步计算模式下,L1D 和 纹理缓存分区的容量也得以倍增。
我们整理了一份自 Fermi 架构到安培架构的 SM 以及 AMD GCN、RDNA 架构的 CU 中的寄存器堆和缓存对比,最下面的是各架构的“线程”资源分配比率:
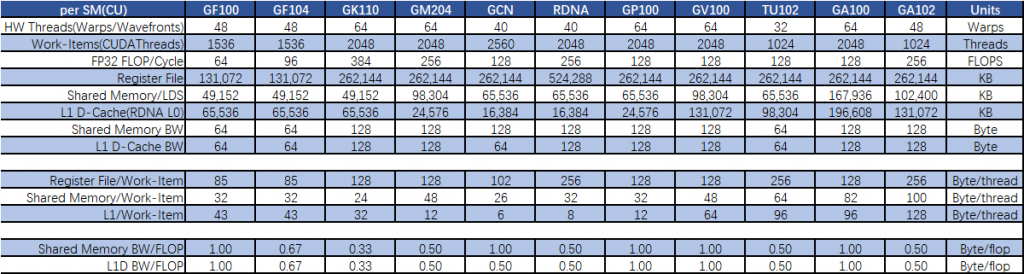
从表格可以看到,NVIDIA 这边的 SMEM 带宽/浮点操作比率在 GF100、GP100、GV100 上都能维持每个浮点操作拥有 1 个字节/周期 的带宽作保证,AMD 的 GCN 比 RDNA 高一倍。
两家公司在这个设计取向上都是让游戏卡产品的 SMEM 带宽/浮点操作作出折让,基本上都是维持在 0.5 字节/周期/FLOPS 附近。
而面向高性能应该用的 GPU,除了 GK100 外,都毫不妥协做到了 1.0 字节/周期/FLOPS。
NVIDIA 的每线程 Shared Memory 可分配容量除了 GK110 只有 24 字节外(相当于 6 个 32 位浮点数)外,都能保持在 32 字节以上,在 GM204 后,这个规模逐步提升,到了安培架构这边,已经提升到每线程可用 100 字节(25 个 32 位浮点数)。
NVIDIA 从 GV100 开始,每个线程的最高可分配 L1D 缓存数也开始显著提升,GA102 已经达到每线程 128 字节,而 AMD 的 RDNA 只有每线程 8 字节,这在一定程度上是由于 AMD 的 L1D 一直采用独立设计。
ROP 方面。ROP 的含义就是光栅操作处理器,是 GPU 里最必不可缺的单元之一,负责色彩混合和多重采样。
在 NVIDIA 以前的 GPU 中,ROP 和 L2 Cache 是绑定在一起的。
在 GA10X GPU 里,ROP 和 GPC 绑定在一起了,这样的设计有利于提升 ROP 的总光栅操作性能,避免了前端的扫描转换单元和后端的光栅操作单元数量不匹配的尴尬。
GA10X 的每个 GPC 有 16 个 ROP,完整的 GA102 包括了 112 个 ROP,相比较之下,上一代的 TU102 在 384 位内存总线全开的情况下也只有 96 个 ROP。
采用这样的新设计,让 GPC 更像一个独立的 GPU,有助于提升多采样抗锯齿、像素填充率以及色彩混合性能。
架构变化——第二代光线追踪内核
上一代或者说图灵架构最瞩目的变化是引入了硬件光线追踪加速单元——RT Core。
光线追踪被认为是可以完美再现真实世界的渲染技术,它的算法符合物理规律,不会像光栅化渲染那样容易产生各种问题以及为解决这些问题后又不断追加修正算法的情况,例如,光栅渲染时阴影和物体的衔接处容易出现悬空以及诸如边缘毛刺等问题。
但是光线追踪最大的问题是需要消耗巨大的计算资源,射线从摄像机发射穿过屏幕像素直达场景后,需要从存储器中查找会被射线击中的三角形,而且每条射线都要做这个动作,如果希望效果好的话,每像素可能还需要若干条甚至上万条射线。
如果场景里有几千万个三角形,逐个三角形做遍历求交,就需要消耗大量的高速缓存和总线带宽,计算单元需要浪费大量时间等待三角形数据传输。
这就好像我们要拼一个几千万个散乱图块的拼图,我们需要逐个图块比对,直到找到相邻的图块,对个人电脑来说以这种办法实时光线追踪是遥不可及的。
为此,人们提出了很多数据结构和算法,希望将遍历求交的次数显著降低,其中被认为最适合实时光线追踪渲染的就是采用 BVH 加速结构体,即多层包围盒体。
BVH 的原理很简单,就是把场景中不同的物体按照层次关系逐个定义包围盒,例如场景里有汽车,骑单车的人,我们可以将三者框在一起,称之为包围盒 A,汽车定义为 B,单车和人合在一起定义为 C,单车和人分别定义为 D 和 E,在此基础上,再继续细分,直到构成模型的三角形。
采用 BVH 后,遍历求交规模会显著减少,例如斯坦福大学 100 万三角形规模的弥勒佛模型可能只需要遍历求交 10 层 BVH 深度就会发生射线有效击中三角形的情况,相当于要对场景中上百万个三角形都做求交测试的情况,性能自然是天壤之别。
还是以拼图为例的话,BVH 就好像拼图在出厂的时候将相近的图块打包在一起,只要图块打包的关系清晰,我们完成拼图的时间就可以显著减少,当然你还可以考虑使用乐高积木为例子。
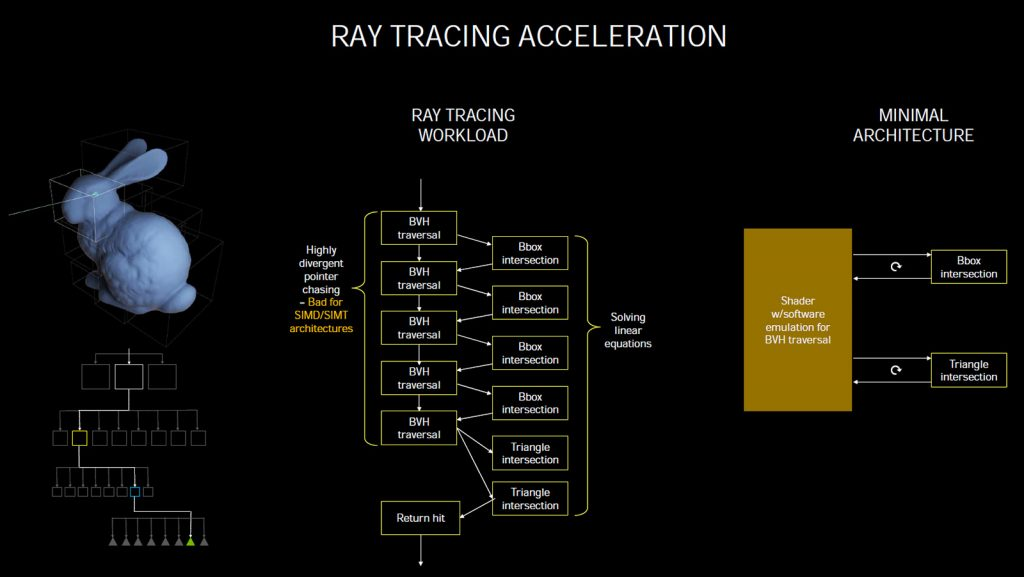
上图是以前图灵架构发布时曾经引用过的幻灯片,图中的兔子被分成若干份 BVH,如果射线没有集中 BVH 的话,那就意味着射线没有集中该 BVH 内的任何三角形,这条射线无需进行进一步的 BVH 和三角形求交计算
图中央的流程图是 BVH 模式下光线追踪的流程,右边则是将这个流程映射到 GPU 上用 SM 或者说软件方式跑的简化流程图。
然而,这种计算并不是很适合 GPU,因为 GPU 是以 SIMT 方式跑指令的,每条指令的宽度是 32 路,BVH 这种本质上是一堆连环指针遍历的数据结构在这种架构上的效率会比较差,因为你可能只能跑出 1/32 的有效求交结果。
而图灵引入的 RT Core 就是专门针对 BVH 数据结构提供的硬件加速方案。
RT Core 提供了 BVH 遍历、BVH 求交、三角形求交、结果返回等过程的硬件加速,图灵配备的第一代 RT Core 可以每个周期完成一次三角形求交,由于每个 SM 都配备有一个 RT Core,在 12 纳米制程的 GeForce RTX 2080 Super 上,三角形射线求交的底层性能是:
1 Triangle Intersection per RT Core * 1 RT Core per SM * 48 * 1815MHz = 87.21 GTriInter/s 
有人曾经根据 TU102 和 TU106 芯片图分析,认为每个 TPC 里的 RT Core 面积大约是 0.8 平方毫米,由于每个 TPC 里包含有两个 SM,每个 SM 配备一个 RT Core,相当于每个 RT Core 面积大约是 0.4 平方毫米。
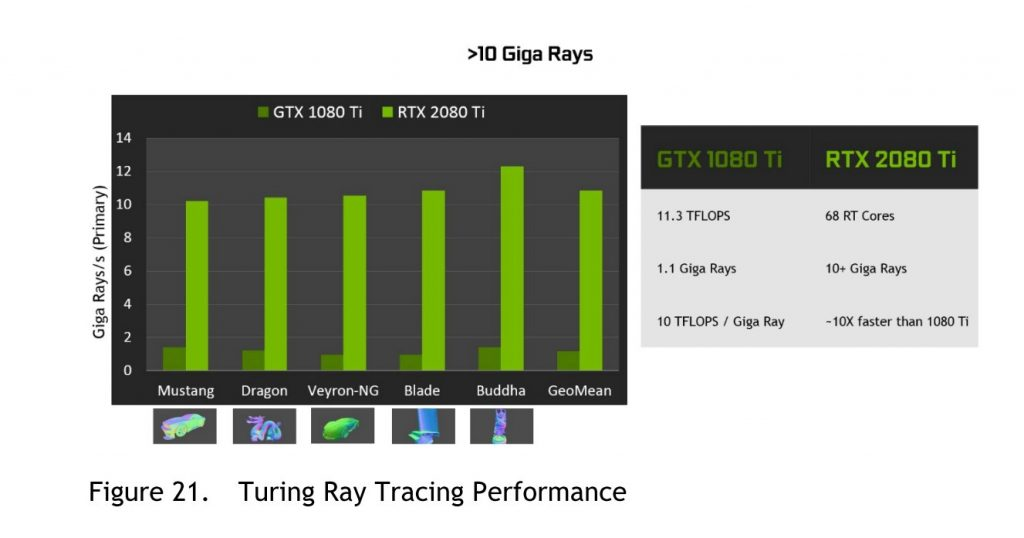
对于拥有 36 个 TPC 的 TU102 来说,RT Core 的整体面积占用低于 4%(0.8mm^2 * 36 TPC / 754mm^2),相对于完全使用着色器来做光线求交的方式而言,RT Core 能够以 4% 不到的芯片面积实现 10 倍于着色器跑光线追踪的性能(以斯坦福大学的弥勒佛模型为例,使用 DXR 进行完整渲染,TU102 12 GigaRay/s vs GP102 1.1 GigaRay/s),效费比还是非常划算的。
安培架构的 RT Core 在图灵架构的基础上将三角形求交模块数量增加到两个(以并行方式运作),同时还增加了一个三角形位置内插模块。
对于具有 68 个 SM、频率为 1710MHz 的 GeFore RTX 3080 来说,意味着三角形射线求交底层性能提升到了:
2 Triangle Intersection per RT Core * 1 RT Core per SM * 68 * 1710MHz = 232.6 GTriInter/s在 BVH 求交模块数量不变的情况下,NVIDIA 给安培增加 RT Core 中的三角形求交模块数量以及增加三角形位置内插模块,目的是提高运动模糊等多次采样特效时的光线追踪性能。
至于为何没有增加包围盒模块,按照 NVIDIA 在媒体技术会上的说法,这是因为他们觉得图灵的包围盒速度已经非常满意,真正的瓶颈卡在三角形求交上。
运动模糊在游戏中是常见的特效之一,它可以模拟物体快速运动时在人类视觉系统中形成的残像效果,例如电影蝙蝠侠中的飞跃动作等。
以往使用光栅渲染做运动模糊特效的时候,例如缺乏真实感的杂噪、重影/条纹伪影、在反射和半透明材质上运动模糊效果缺失。
如果使用光线追踪做运动模糊特效的话,效果会更加真实准确,没有多余的伪像。但是使用光线追踪跑运动模糊需要很长的时间,尤其是在没有硬件加速执行模糊效果所必需的光线追踪操作的情况下。
光线追踪运动模糊可以采用多种算法来实现,其中比较流行一种方式就是将许多带有时间戳的射线以随机方式发射到场景中。
支持运动模糊功能的 BVH 会针对在一段时间内移动的几何体返回射线的命中信息,其命中信息的采样与每条射线相应的时间戳相关。到了着色阶段,前面获得的采样数据会被合并至最终的模糊效果里。
这样的算法有相当多的实现方式,NVIDIA 的 OptiX 自从 5.0 版(2017 年)开始就支持这样的技术。
对于镜头围绕静态物体发生平移、旋转、缩放产生的运动模糊,人们一般称之移镜模糊,上一代或者说图灵 GPU 能够很好地加速移镜模糊:只需要在一定时间间隔内尝试将多束射线打进场景到静态几何体上,RT Core 就能完成 BVH 遍历加速、执行射线/三角形求交测试,然后将是否击中的结果返回,从而实现模糊效果。
但是,如果场景中的物体是移动的话,BVH 的信息也会随之变化,这会带来更大的挑战。
GA10X 引入的第二代 RT Core 增加了新的内插模块,在允许 BVH 内的数据做少量更新的情况下,就能实现移动物体运动模糊效果的显著性能提升。在 OptiX 7.0 中,开发人员可以为几何体指定特定的移动路径,让每条射线和时间关联起来,从而实现移动物体的所有运动模糊效果加速。
图灵和安培的 RT Core 都采用了 MIMD 架构,能在同一时间内跑多条射线。
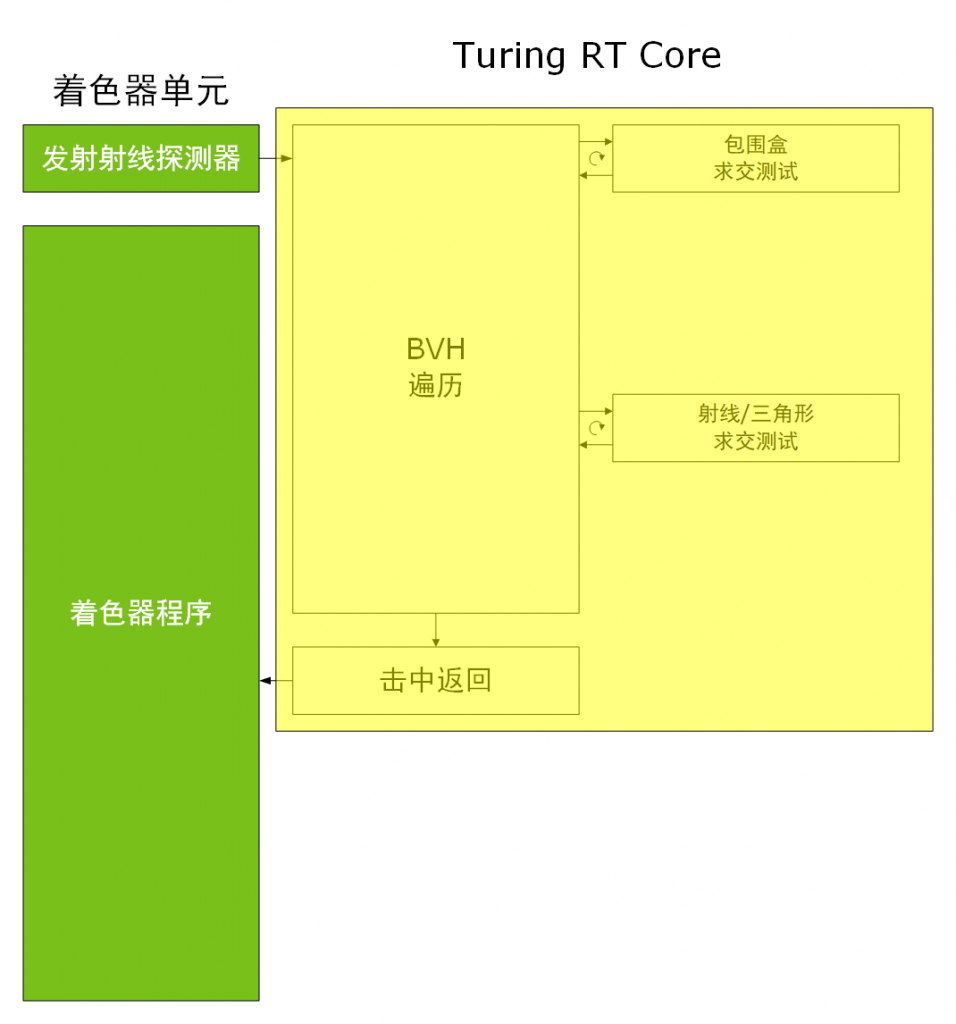
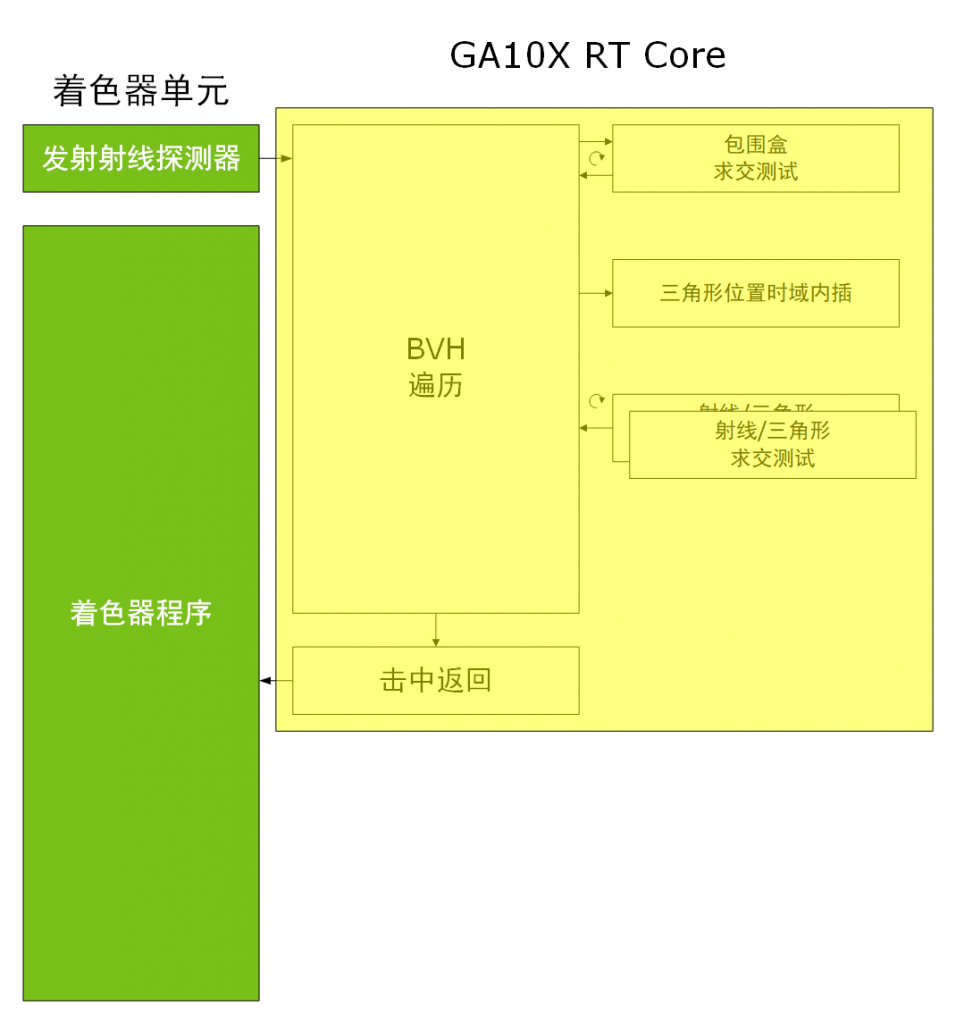
上图是两个架构在光线追踪执行示意图,可以看到安培的 RT Core 增加了一个三角形位置时域内插,三角形射线求交模块增加到两个。
光线追踪执行运动模糊的难题在于光线追踪所采用的 BVH 结构体。
一般情况下,BVH 里三角形的位置是已经定义好的,RT Core 执行包围盒射线求交测试和三角形射线求交测试后,如果击中了三角形,就会执行采样并返回命中信息。
但是运动模糊特效里三角形不再有固定的位置,此时 BVH 内的公式是:告诉我当前是什么时间,我可以告诉你这个三角形的位置。
每一条射线都需要带有一个时间戳,用于指示追踪发生的时间,时间戳输入到 BVH 方程内,就能获得三角形的位置,从而完成三角形射线求交计算。
如果 GPU 内没有集成相应的硬件加速单元,这个步骤就会成为一个瓶颈,NVIDIA 认为这足以构成一个世代的差别,而且动态模糊对性能的影响还是非线性的,例如我们要对旋转的螺旋桨或者车轮寻找三角形位置。
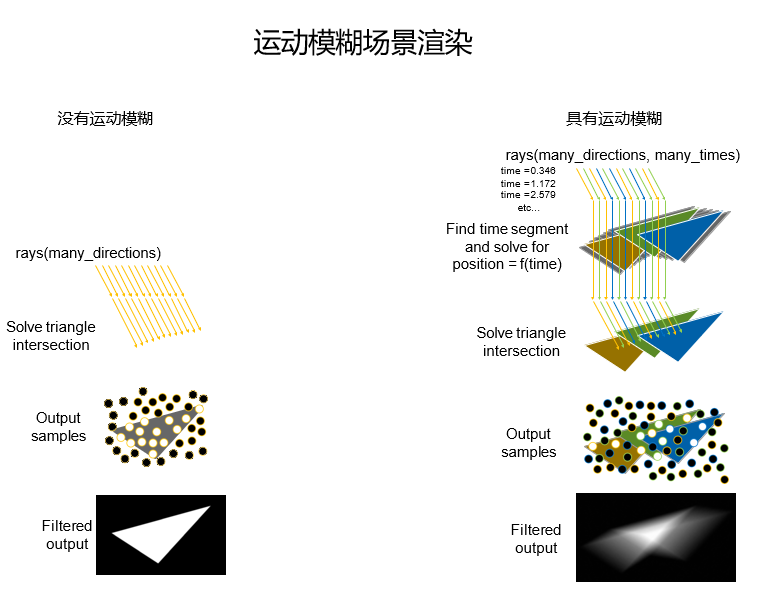
上图的左侧展示的是没有运动模糊时候的光线追踪渲染,这是在一个没有运动模糊的场景中投射多条射线,这些射线的许多条都击中了三角形,这些被称作 Output samples 的结果会用于着色计算,图中的白点代表了射线击中了该三角形的位置。
右侧表示场景采用了运动模糊的情况,可以看到每条射线都存在于不同的时间点,这些射线我们用橙色、绿色、蓝色分类表示,各射线都有自己的时间戳。
橙色射线:尝试在不同的时间点上对橙色三角形求交
绿色射线:尝试在不同的时间点上对绿色三角形求交
蓝色射线:尝试在不同的时间点上对蓝色三角形求交这就是光线追踪的运动模糊实现,经过这样的处理,模糊的计算结果会更加理想,属于数学正确的滤波输出结果——底下的 filterd output 就是该算法(让射线在不同的时间点上的不同位置击中三角形产生的混合样本)输出结果。
根据在渲染器 Blender Cycle 中的实测(场景 The Car Copter 25),RTX 3080 运行带有运动模糊特效场景的渲染时间从 RTX 2080 super 的 14 分钟缩短到 6 分钟,其中运动模糊部分带来的提升就达到了 5 倍。
除了增加三角形位置内插模块以及三角形求交模块以外,安培配备的第二代光线追踪内核还支持和 SM 运算单元异步并发执行。
相信很多人都知道,现在的 GPU 里一般有两种命令处理器,分别用于处理计算指令和图形指令的派发,对应通用计算流水线和图形流水线,光线追踪内核属于图形流水线。
异步计算的初衷是假设当前 GPU 里同时有图形计算(例如顶点、像素渲染)任务和通用计算(例如物理、音频)任务,如果其中一个任务卡在流水线前端(front-end)的固定功能单元上的话,例如图形任务需要先在光栅单元上执行光栅化处理,流水线余下的着色器虽然可以用于通用计算,但是会处于空闲等待的状态。
为了将这些不同任务属性的资源充分利用起来,人们提出了异步计算,在图形指令还在前端或者固定功能单元里跑的时候,通用计算命令处理器可以将通用计算队列派发到 SM 里的 CUDA Core 跑。
NVIDIA 在 Pascall 架构上引入了动态负载模式,不过相对于 AMD 的 GPU 架构而言,NVIDIA 的光栅器资源更多,出现卡在图形流水线前端的情况会少一些,因此这时候 NVIDIA 的 GPU 给人的印象是采用异步计算带来的收益会相对少一些。
我们前面说过,RT Core 加速的是光线追踪里的求交测试,这个任务的本质是确定场景里三角形的可视性(主射线实现)以及周边环境(其他物体、光源)对它造成的影响(次生射线实现),这是光线追踪最繁重的任务(占了光线追踪渲染 70% 以上的处理量)。
但是光线追踪渲染余下的特效计算依然需要由 SM 等单元来实现,例如反射倒影、折射、阴影混合、降噪等等,相对于传统光栅渲染来说,SM 需要处理的计算任务一点都没减少甚至更多。
在图灵架构中,RT Core 允许和 SM 采用异步计算的方式执行光线追踪渲染,例如当第 128 号屏幕像素的求交测试任务在 RT Core 上执行的时候,SM 可以对第 96-99 号屏幕像素进行光线追踪渲染处理(像素编号只是便于举例,别较真...),采用异步计算可以有效提高 GPU 计算资源的利用率,从而提升性能。
GA10X GPU 对前代 GPU 已经具备的异步计算予以增强,实现了 RT Core + 图形或者 RT Core + 计算都能在每个 SM 里并发执行。
相较之下,在图灵架构里 SM 只能实现图形 + 通用计算(例如顶点/光栅/纹理取样 + CUDA Core)的并发执行,如今 GA10X 提供了更灵活的并发执行能力,例如在用 RT Core 跑光线求交的同时让计算单元跑路径追踪(Path Tracing,光线追踪用于全局照明的一种算法)降噪。
简而言之,现在安培架构里的所有 "Core" 都能实现异步运算,这意味着在安培架构里,CUDA Core + RT Core + Tensor Core 是可以异步计算的方式并发运行,NVIDIA 称之为第二代并发执行。
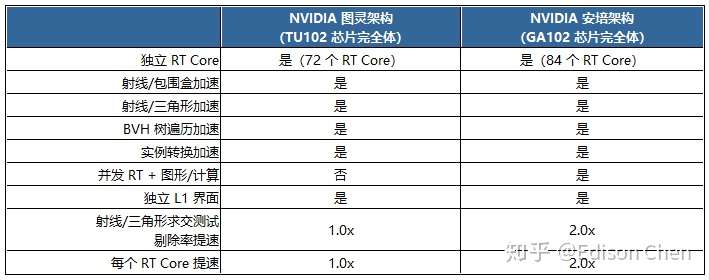
上面的表格就是安培 RT Core 和图灵 RT Core 的规格对比。
NVIDIA 以游戏 Wolfenstein: Youngblood(德军总部,新血脉)为例,对比了 Pascal、Turing、Ampere 三个架构在同一个场景中的渲染时间片。
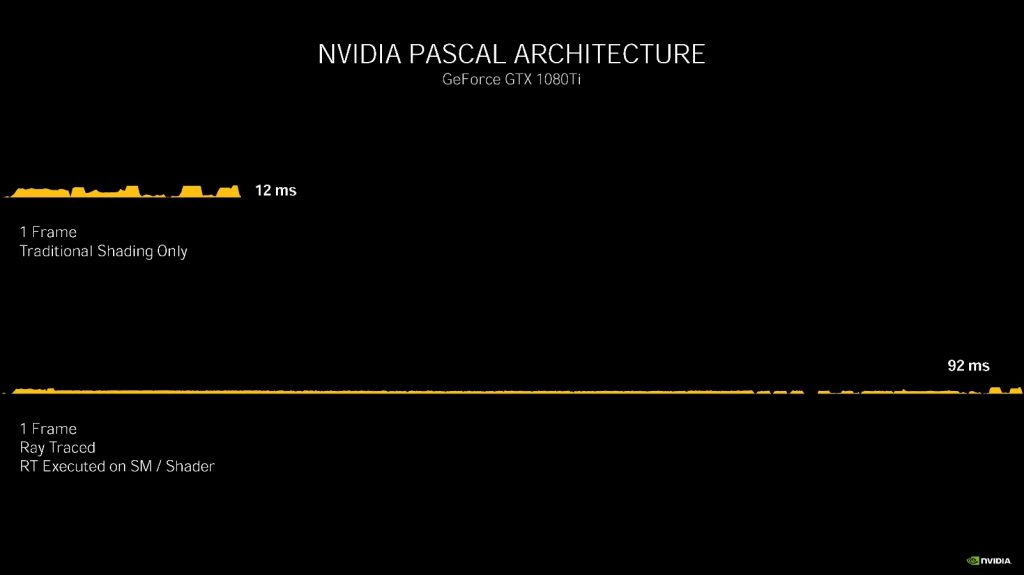
在 Pascal 架构的 GTX 1080 Ti 上分别使用传统光栅渲染和光线追踪(着色器执行)渲染一帧分别需要 12 毫秒(83 fps)和 92 毫秒(11 fps)。
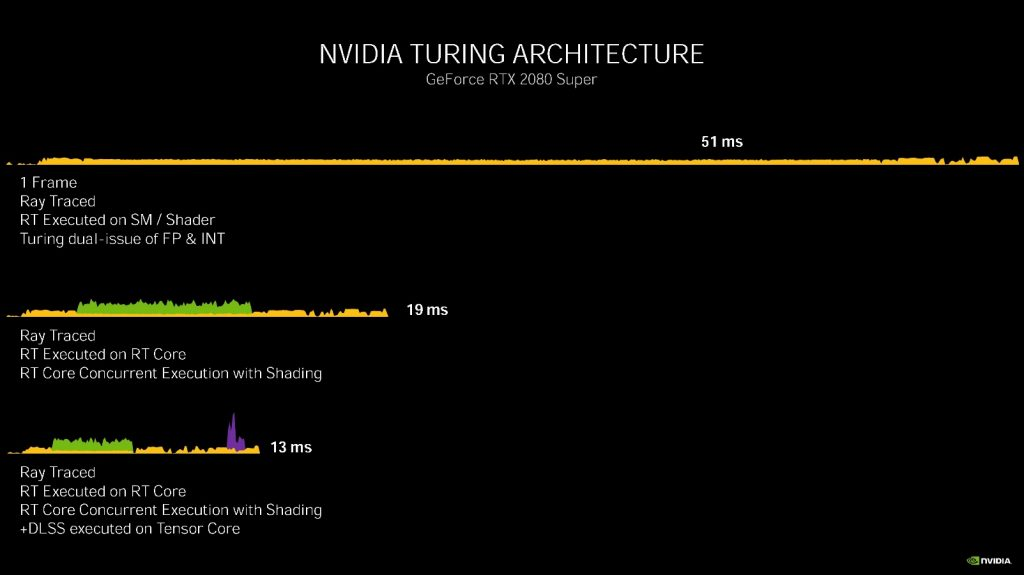
在 Turing 架构的 RTX 2080 Super 上:
光线追踪(着色器执行):51 毫秒(20 fps)
光线追踪(RT Core + CUDA core 着色并发执行):19 毫秒(53 fps)
光线追踪 + DLSS((RT Core + CUDA core 着色并发执行)+ Tensor Core ): 13 毫秒(77 fps)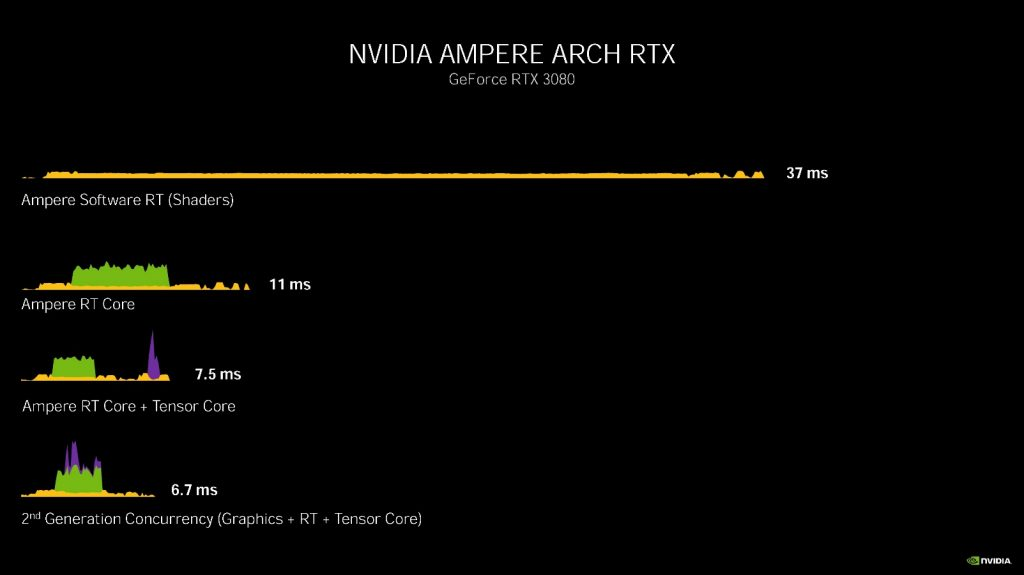
在 Ampere 架构的 RTX 3080 上:
光线追踪(着色器执行):37 毫秒(27 fps)
光线追踪(RT Core + CUDA core 着色并发执行):11 毫秒(90 fps)
光线追踪 + DLSS((RT Core + CUDA core 着色并发执行)+ Tensor Core ): 7.5 毫秒(133 fps)
光线追踪 + DLSS(RT Core + CUDA core 着色 + Tensor Core 并发执行): 6.7 毫秒(149 fps)正如你所看到的,Ampere 架构下的 RT Core 现在能够实现 RT + 图形 + Tensor Core 并发执行,能够让帧率有效提高,在这样的模式下,RTX 3080 光线追踪渲染甚至比 GTX 1080 Ti 使用传统光栅渲染还要快接近一倍。
性能增益还是不错的,值得一提的是,Wolfenstein: Youngblood 这个游戏按照官方的介绍,只有 2-4 名全职开发人员,开发时间只有 9 个月。
架构变化——第三代张量内核
NVIDIA 自 Volta(伏特)架构开始引入名为 Tensor Core(张量内核)的模块,它是专门针对深度学习加速设计的矩阵运算单元。
在图灵架构里,NVIDIA 引入了第二代 Tensor Core,和 Volta 的第一代 Tensor Core 相比,图灵的 Tensor Core 支持更多低精度(INT8、INT4)操作,这是因为有些推理运算可以容忍较低的运算精度。
作为面向消费级的产品,图灵架构引入 Tensor Core 当然不是只是将人工智能装点门面,它有非常实际的用处,例如基于深度学习的光线追踪降噪以及基于深度学习的 DLSS 抗锯齿渲染。
图灵每个 SM 都配有 8 个 Tensor Core(每个子核有两个 Tensor Core),每个 SM 每个周期可以跑 512 个 FP16 Tensor 操作。
安培架构的每个 SM 里有 4 个 Tensor Core(每个子核有一个 Tensor Core),但是每个 Tensor Core 的处理能力都倍增了,因此安培的每个 SM 也能跑 512 个 FP16 Tensor 操作。
在数据格式支持能力方面,安培引入了 BF16、TF32 两种新的数据格式,前者是 Google 引入的一种 16 位数据格式,而后者则是 NVIDIA 自家首次引入的 19 位数据格式。
FP、BF、TF 里的“F”表示数据是浮点形式,它们的表示格式由三段组成,分别是符号位、指数位和尾数位组成。
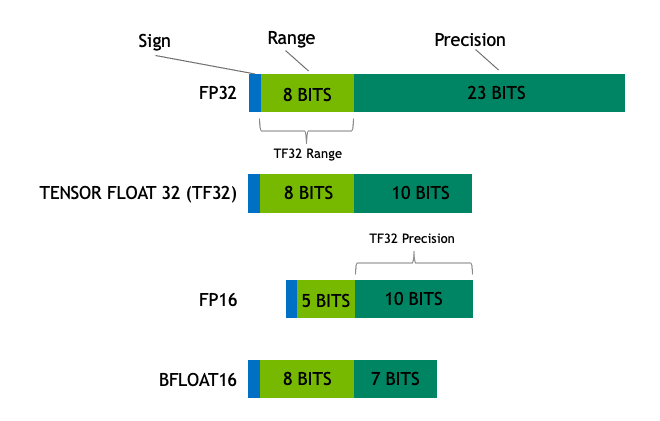
FP16:又被称作半精度,1 个二进制符号位,5 位二进制表示指数,10 位二进制表示尾数,一般用于图形渲染,在深度学习中也被广泛采用。
BF16:也被称作 Brain Float 16 或者 BFloat 16,由 Google Brain 推出,最初只有谷歌的 TPU 深度学习处理器采用。和 FP16 一样,BF16 也是 16 位长的二进制数,但是它的数据格式是 1 位符号位、8 位指数,7 位尾数。这样的设计是为了追求 FP32 的动态范围,但是需要牺牲尾数数据范围。
TF32:这是 NVIDIA 在 A100 厨房发布会首次公布的数据格式,目前已发布的安培全系 GPU 配备的 Tensor Core 都支持这个数据格式。TF32 的数据格式是 19 位二进制,有 1 个符号位,8 位指数以及 10 位尾数。
TF32 具备 FP32 和 BF16 一样的 8 位动态范围,但是有效数字精度比 BF16 多了 3 位,如果以十进制来说相当于有效数字精度从两位提高到了接近四位。
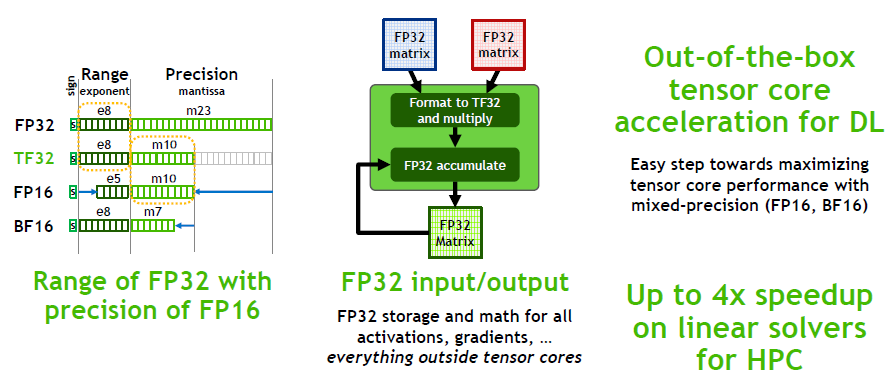
在具体实现上,在启用 TF32 的时候,NVIDIA Tensor Core 输入输出的数据格式依然是 FP32,但是 Tensor Core 内部会以 TF32 的格式进行计算,因此,TF32 无需程序员修改代码,只需要编译器提供支持即可,和 FP32 相比,TF32 只是精度降低,但是动态范围保持一样,而性能和 FP16 Tensor 性能一样。
由于数据格式的原因,FP16 和 BF16 都需要更多的代码量,但是因为可以节省内存占用以及更快的速度,所以 BF16 和 FP16 依然值得采纳。
除了支持更广泛的数据格式外,A100 引入的硬件稀疏化技术在 GA10X 上也得以实现,透过该技术,GA10X 在同样每周期 512 个 FP16 tensor 操作的能力上可以再增加一倍达到等效每周期 1024 个 FP16 操作。
和 RTX 2080 Super 相比,RTX 3080 的张量性能可以最高达到 2.7 倍。
和 A100 相比,作为面向消费级市场的 GA10X 去掉了 A100 的 FP64 以及 Binary(二元)张量计算支持。
GA10X 的 Tensor Core 数量是 TU10X 的二分之一,但是由于每个 Tensor Core 规模是前代的两倍,因此跑同样格式的数据性能都是一样的,例如 FP16 的时候都是每个 SM 每周期跑 512 个 FP16 tensor Ops。
比较特别的是,GA10X 具备 A100 一样的硬件细粒度结构化稀疏加速能力,能够以每 4 个权重为一组的方式,将已经训练好的权重分组中权重值为 0 的两个权重修剪掉,透过这个稀疏化处理,实现了推理准确无损情况下等效 100% 的深度学习性能提升,或者说等效每周期每个 SM 完成 1024 个 FP16 Tensor 操作。
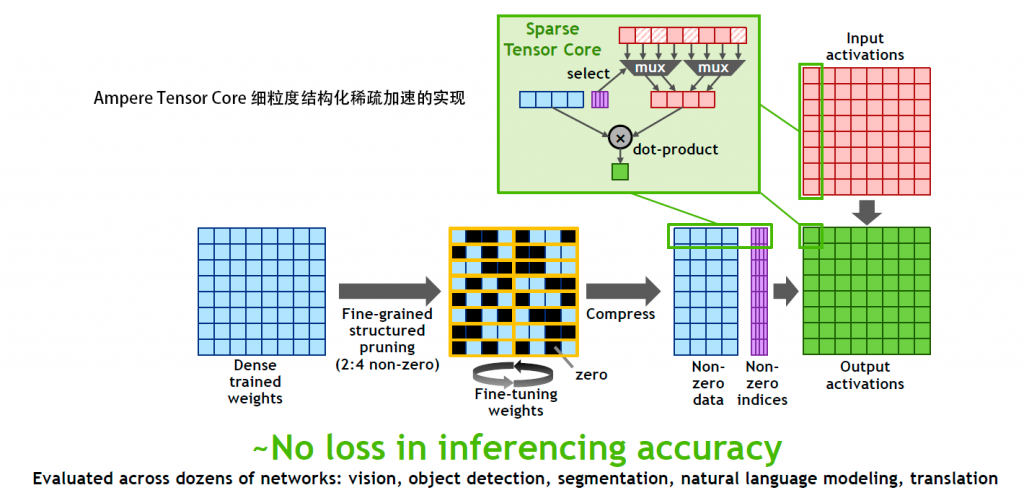
不过 Ampere 的细粒度结构化稀疏只能实现 50% 的修剪,遇到分组中有较多非零权重的时候,就需要手工修改代码做优化,也许未来的新架构会在这方面有更高的灵活性。
按照 NVIDIA 的说法,细粒度结构化稀疏对于跨视觉、目标检测、自然语言建模以转译等多种神经网络应用都几乎不会造成推理准确度的损失。
全面改善游戏载入性能——RTX IO
现在许多大作级游戏已经是动辄 50 GB 以上的硬盘占用,随着互联网网速的发展以及人们对游戏精细度的不断追求,例如现在的 Call of Duty: Modern Warfare 就要吃掉 200GB 的硬盘空间。
另一方面,现在的固态硬盘性能也越来越高了,像 PCIE 4.0 X4 的 NVME SSD 就可以达到 14GB/s 级别的读写性能。
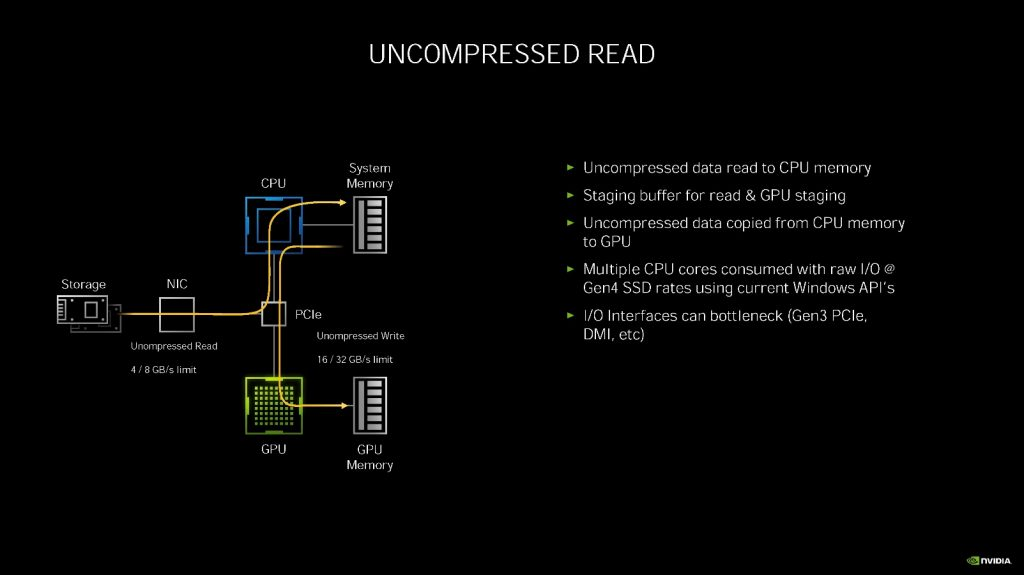
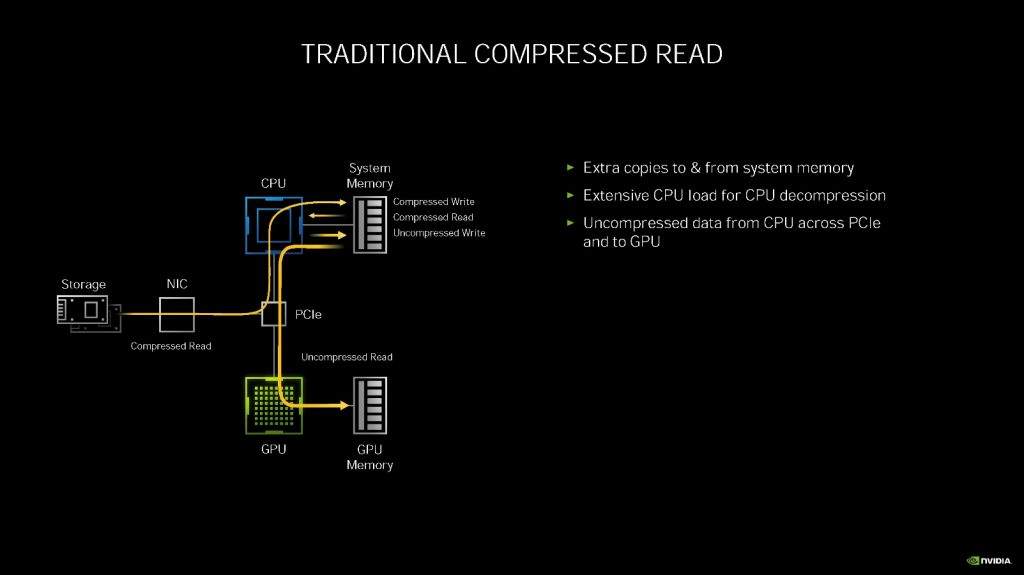
随之而来的问题目前的存储协议跟不上形势发展了。目前的游戏大都会采用压缩方式保存数据,GPU 要获得硬盘上的数据,首先需要硬盘把压缩的数据发送给 CPU,CPU 将数据解压缩后,放到系统内存中,然后 GPU 把数据抓到显卡的显存中。
NVIDIA 认为,对 PCIE 4.0 总线所能传输的 14GB/s 的压缩数据进行解压缩需要完全吃掉 24 个 CPU 内核(AMD ThreadRipper)。
为了解决这个问题,NVIDIA 之前曾经针对自己的 GPU 集群系统 DGX-2 提出 GPUDirect Storage(简称 GDS)技术,让 GPU 直接透过 PCIE 总线读取 NVME SSD 上的数据,主要应用于一些海量数据的处理,例如多普达雷达数据。由于该技术依赖于以往 Tesla、Quadro 上才有的 GPUDirect 技术,因此之前并未在消费类 GPU 上看到。
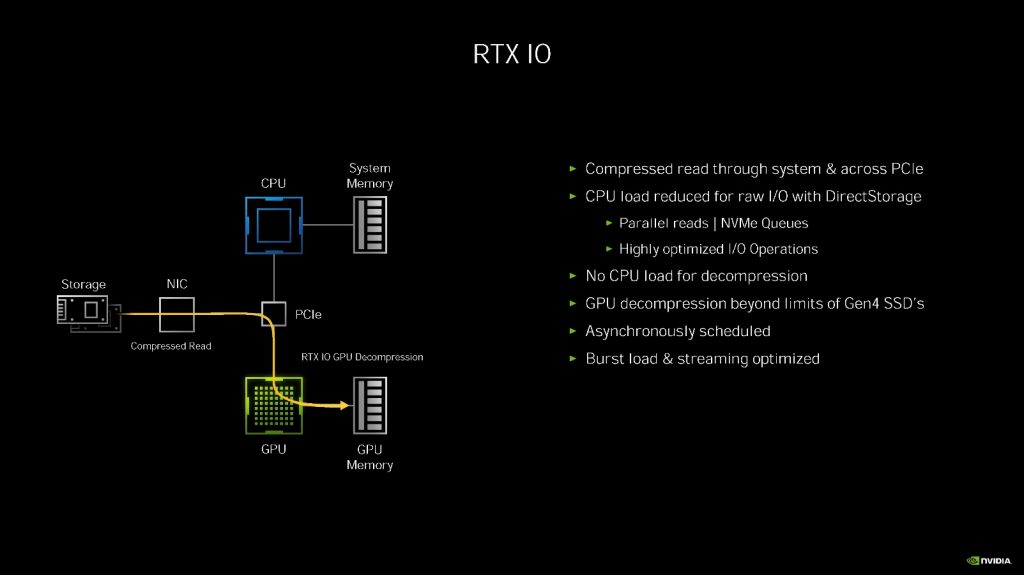
不过到了这次安培 GA10X 发布会上,NVIDIA 宣布了该技术的游戏卡版本 RTX IO。
NVIDIA RTX IO 是一组针对游戏数据资产的 GPU 载入及解压缩方案,可以与微软明年的 DirectStorage 配合,实现游戏数据载入效能的显著提升,目前只针对图灵和安培架构提供该技术。
相对于下一代游戏主机采用专门的硬件解压缩单元,目前图灵和安培架构 GPU 的 RTX IO 都采用 GPU 进行无损数据解压缩,A100 里集成的 NVJPG Jpeg 编解码器在 GA10X 上欠奉。GPU 从硬盘直接读取压缩数据,然后由 GPU 进行解压。
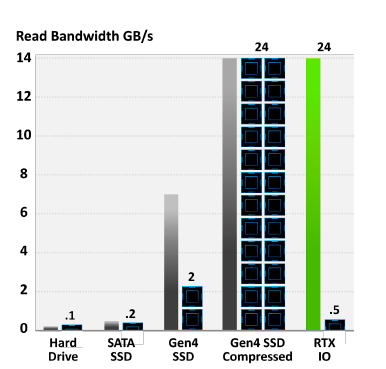
按照 NVIDIA 提供的图表,RTX IO 可以在只占用半个 CPU 内核的情况下,完成和 24 个 CPU 内核相当的传统传输+解压缩操作。
这其中自然是利用了图灵和安培架构的 DMA 和 copy 引擎、高级指令以及 SM 架构上的优势,例如利用了 GPU 的异步计算,用闲置的 SM 单元进行无损解压缩。
和 GPUDirect Storage 相比,RTX IO 的特点主要是面向游戏为主,例如一些游戏数据的 GPU 解压缩功能将透过微软 DirectStorage 等方式提供给游戏引擎开发人员。
在游戏关卡载入以及采用了流式地图、场景的游戏里,RTX IO 配合 NVME SSD 能够提供比传统存储协议高得多的性能,像前面提及的 7GB/s 压缩数据的解压缩,使用 RTX IO 后,CPU 占用率会从 24 个 ThreadRipper CPU 内核完全吃满降低到半个 CPU 内核。
拥有强大直读和解码性能的 RTX IO 能给游戏带来什么变化呢?
首先,最显而易见的就是游戏的场景、模型、纹理会变得前所未有的精致,某种程度上这个技术给玩家带来的变化感受可能不亚于 Ray Tracing,当年 S3 为 Quake 3 Area 推出了一个 S3TC 高分辨纹理地图,进去后我感觉这游戏以前白玩了。

NVIDIA 这次发布 RTX 3000 系列的时候有一个名为 Marble Night 的完全光线追踪演示程序,其中包含了数以百计的光源和超过一百万多边形。采用传统存储协议 NVME + CPU 解压的话,载入时间为 5 秒,采用 RTX IO NVME + GPU 解压,载入时间缩短到了 1.6 秒。
RTX IO 的另一个应用场景就是非线性编辑和舞台巨幕,三年前 AMD 就推出过一款后缀带有 SSG 的专业卡,其中内置了一块 SSD,专门针对 8K 视频编辑。现在消费级显卡有了 RTX IO 后,硬盘数据无需 CPU 参与就可以被 GPU 直接读取解码输出,很多相应的专业应用如今也有机会以比较低的成本得以实现。
首次采用 PAM4 技术——GDDR 6X 内存
作为针对吞吐先决应用的产品,显卡的性能在很大程度受制于内存带宽,纹理、色彩混合、多重采样等不可或缺的 GPU 渲染操作都需要频繁读写显存。
为了满足 GA102 对内存性能的需求,NVIDIA 和镁光一起联合开发了全新的 GDDR 6X 内存规格,实现了常规内存接近 HBM 内存的带宽。
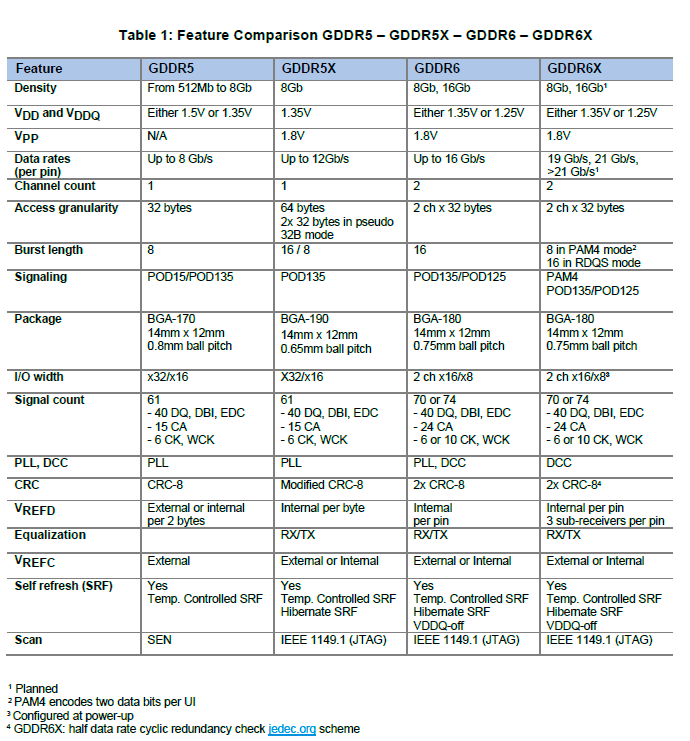
GDDR 6X 或者说 G6X 采用了和 2018 年推出的 GDDR 6 一样的数据访问粒度和颗粒尺寸,主要改进了数据速率以及传输效率,能实现超过 900 GB/s 的板载内存带宽。
GDDR 6 内存为了实现 16Gbit/s 的引脚数据速率,可用的数据捕获时间窗口只有 62.5 纳秒甚至更低,使得实现该频率需要额外的电路电平来确保精度和复杂度,如果继续采用类似的技术来获得更高的引脚数据速率,面临的电路设计挑战将会异常巨大,成本也会急剧提升。
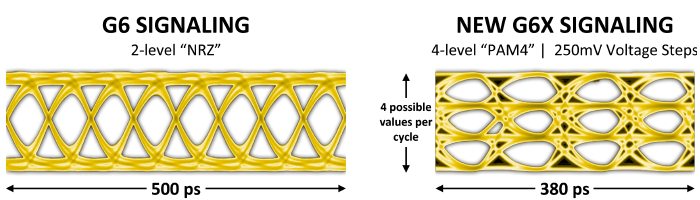
为了克服 GDDR 6 的计时挑战,GDDR 6X 引入了名为 PAM4 的数据传输机制,相对于 GDDR 6 的 PAM2(或者说 NRZ)而言,每个数据传输周期的数据符号率增加到了两个二进制位,经过这个改进后,结合 MTA 以及新的编码、算法和布线设计,GDDR 6X 可以实现 19Gbps 甚至 21Gbps 的引脚数据速率。
和采用 GDDR6 的 TU102 旗舰卡 GeForce RTX 2080 Ti 相比,采用 GDDR 6X 的 GA102 旗舰卡 GeForce RTX 3090 内存带宽提升到了 936 GiB/s,提升了 52%,对于 RT Core 执行的 BVH 遍历等应用会有非常大的助益。
面向 8K——显示输出及视频编解码引擎
GA10X 的显示引擎支持 DisplayPort 1.4a 和 HDMI 2.1,去年曾经流传出 TU10X 可以透过软件升级实现 HDMI 2.1,但是到目前为止没有落实,反正 TU10X 就是不支持 HDMI 2.1。所
以 RTX 3000 系列是当前唯一实现了 HDMI 2.1 支持的独立显卡。
有了 DP 1.4a 和 HDMI 2.1 后,RTX 3000 既能够以每台均为单线缆的方式支持两台 8K 60Hz 显示器或者电视机、投影仪。
8K 目前的主要应用是内容创作,例如 8K 视频非线性编辑以及亿级像素图片的后期处理,此外还有一些界面中有大量很多选单和空间的应用,都是非常适合 8K 显示器,例如佳能的 EOS R5 已经提供了 8K RAW 视频录制。
8K 内容目前并不多见,Youtube 上有些 8K 样片,而国内 B 站目前只开放到 4K 120FPS。按照当年 UHDTV 的最初计划,真正的目标是 8K,4K 只是过渡,2020 年被业界设定为 8K 元年,像奥运会都将采用 8K 直播,但是因为疫情的关系,这波 8K 电视大促会被明显受影响。
令人高兴的是,中国去年的国庆 70 周年活动是全球首次全程 5G + 8K 直播(8K 采编,4K 地面直播),估计这场活动以后会有 8K 版的正片发布。按照之前看到的计划,央视今年会全部 4K 直播,预计明年开始试水 8K 直播。
GA10X 集成了一个第五代 NVDEC(NVIDIA 视频解码器),可以支持多种流行编码的视频,显卡集成硬件解码器的好处是可以显著释放 CPU 资源,提升播放体验、增强转码性能(NVDEC 能够用比原视频快得多的速度解码),同时降低系统播放视频时候的功耗。
在视频播放方面,第五代 NVDEC 除了以前已经实现了的 HEVC、AVC、MPEG2、VC1、VP8、VP9 等视频的硬件解码外,还新增了 AV1 硬件解码。
AV1 是 AOMedia(基本都是电脑行业的公司)推动的免授权金视频编码标准,相同画质下的视频压缩能力介乎于 AVC 和 HEVC 之间。
Youtube 上已经提供了 AV1 视频格式支持(需要手动在后台切换),国内爱奇艺今年 5 月份开始正式在 PC、安卓端全面采用 AV1,微软 Windows 10 操作系统可以透过应用商店下载 AV1 解码器扩展,而视频爱好者经常使用的 LAV Filter 采用的是 VideoLAN 的开源 dav1d 解码器。
AV1 需要极强的处理器才能实现软件解码,按照 http://phoronix.com 的测试,Core i7 3770K 跑 4K AV1 只能做到 38.3 fps,Core i7 9900K 播放 Youtube 8K 60FPS 的视频只能做到 28fps,相较于 NVDEC 在较低耗电的情况下完全释放 CPU 资源相比,CPU 软件解码并不是好的选择。
GA10X 的 AV1 解码支持能力:
- AV1 Profile 0 - 单色 / 4:2:0, 8/10 bit 解码
- 最高 Level 6.0 (不含大尺寸分块)。
- 最高分辨率支持 8192x8192,最低分辨率支持 128x128
- 支持直方图采集、胶片颗粒合成、自取样映射(SSM)
- 8K 60 fps 硬件解码
- 数据路径支持 DX9、DX11、DX12
在编码能力方面,GA10X 集成了和图灵一样的第七代 NVENC(NVIDIA 视频编码器),支持 AVC、HEVC 视频硬件编码,透过 OBS、NVIDIA Boardcast 等直播软件实现高性能的视频直播,最高可以提供 AVC 4K 和 HEVC 8K 的实时编码支持,压缩画质比 x264 软件解码器采用 Fast 更高。
蓄势待发的 DLSS 2.1 与 8K 游戏
8K 显卡有了,8K 显示器也有了,那么用 8K 跑游戏行不行呢?
8K 分辨率下,像素规模是 4K 的 4 倍,每帧画面高达 3.3 千万像素,如果一个瓶颈主要在显卡上的游戏可以在 4K 分辨率下实现 100 FPS 的话,到了 8K 分辨率的时候,可能就会掉到 25 fps 左右,25 FPS 对于有些游戏来说其实还好,但是对于很多玩家热爱的第一人称射击游戏来说有点太低了。
较有意思的是,NVDIA 自图灵架构引入的 Tensor Core 让流畅运行 8K 游戏成为了可能。
DLSS 的字面意思是深度学习超采样,超采样技术以往在游戏中一般只是用于抗锯齿,事实上 DLSS 最初的版本也主要是实现抗锯齿。
然而到了 2019 年,由 NVIDIA Edward(Shiqiu) Liu 团队实现的 DLSS 2.0 带来了质的飞跃,能够在 1080p 渲染分辨率下提供不亚于 4K 原生分辨率渲染品质的画面。
这次安培发布会上,NVIDIA 发布了 DLSS 2.0 的升级版本 DLSS 2.1,其中就有名为 DLSS 8K 的渲染技术,能够以 2560X1440 的渲染分辨率实现不亚于 8K 原生分辨率渲染品质的画面,画面重构能力从 DLSS 2.0 的 4 倍提高到了骇人听闻的 9 倍。
DLSS 2.0 的原理是在超级计算机上对数以万计的超高品质渲染图片进行训练,获得一个训练网络,然后使用这个训练网络在游戏完成渲染后,对较低分辨率的画面进行重构,生成更高分辨率的画面,重构的画面在细节度方面极高。
按照 Edwad Liu 的说法,现在 DLSS 已经具有极高的泛用性,不需要为每个游戏重新训练,这样可以大大节省开发人员的部署时间。
由于 DLSS 8K 的原图渲染像素数量也就是 1/9 的,因此它的速度要比原生 8K 渲染快得多,即使用上光线追踪,速度也是可以达到 60fps 以上的水平,这已经是相当厉害的水平了。
那么 DLSS 8K 画质如何呢?由于当前驱动还没开放 DLSS8K,因此我们这里先借用 NVIDIA 提供的对比图:


从对比图来看,我觉得渲染品质还是相当不错的,再看看 NVIDIA 提供的实测性能数据:
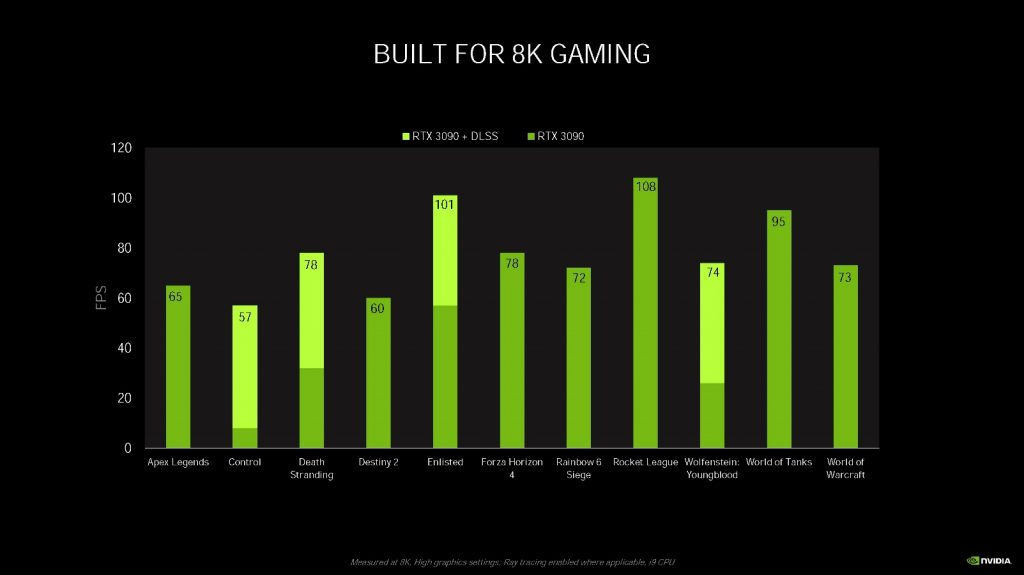
速度基本都能维持在 60fps 的水平,如果不使用 DLSS 8K 而用 8K 原生分辨率来渲染的话,60fps 的速度下相当于每秒跑 20 亿个像素的渲染了,像 Control 已经掉到个位数的帧率了,用了 DLSS 8K 后,帧率提高到了 57 fps。
除了 DLSS 8K 外,DLSS 2.1 还提供了 VR 和动态分辨率的支持,后者可以在维持输出分辨率不变的情况下,将分辨率不断变化的输入画面经过动态重构为输出分辨率。
DLSS 2.1 需要游戏开发人员添加代码才能实现,之前的 DLSS 2.0 游戏只有两个选项:Quality 和 Balance,如果整合 DLSS 2.1 后,玩家可以选择的 DLSS 2.1 选项包括了 Quality(高品质)、Balance(平衡)、Performance(速度)、Extreme Performance(极致速度),分辨率重构倍率分别对应 2x、3x、4x 和 9x。
NVIDIA 表示已经有了多款游戏加入了 DLSS 8K 的支持行列,包括:Boundary、Bright Memory: Infinite、Control、Death Stranding、Justice、Minecraft with RTX Beta、Ready or Not、Scavengers、Watch Dogs Legion 以及 Wolfenstein: Youngblood 等。
此外,安培架构具备的 NVLINK 3.0 如果可以用于组 SLI 的话,应该也能在 8K 游戏中发挥一定助益。
性能与画质兼顾的 RTXGI 全局照明
全局照明是指对场景渲染的时候,将场景中各个物体和光源之间相互作用的复杂效果予以表现。
假设有一个四堵墙和密闭房顶的房间,其中一面墙有一扇窗户,色温为 5500K 的标准日光从窗户打进来,然后房间里的墙壁涂了有颜色的涂料,光线进入房间后,由于漫反射的作用,这些墙壁会将自身颜色的光线反弹到房间的其他角落,那么位于房间中的物体就会受到多种方向光线的影响,在不同角度上呈现不同的染色表现。
光线追踪可以完美再现这个效果,例如使用 Path Tracing(路径追踪),将射线打到房间里,击中墙壁后,用蒙特卡罗法随机发射大量随机方向的次生射线,遇到下一个物体后,继续这个步骤。
当然由于光线能量以反平方差的方式衰减以及物体吸收的关系,实际渲染的时候不需要做无限次反弹,在离线渲染的电影中,一般也就是做 10-15 次反弹就够了。
不过即使如此,路径追踪需要消耗的资源还是太高了,很难在速度和质量间做平衡。
RTXGI 采用的全局照明技术并非 Path Tracing,而是被称作 DDGI(Dynamic Diffuse Global Illumination)的取巧技术,办法和很多其他全局照明的方法类似,那就是加个“球”——给场景里加一大堆探测球。
NVIDIA 这次发布安培架构的时候对 RTXGI 做了特别的介绍,而 Richard Cowgill 还在 9 月 5 号于 Unreal Engine 的 Youtube 频道对 RTXGI 做了接近两个小时的讲解,我觉得这部分也是比较有意思的。
首先让我们来看看开关 RTXGI 前后的对比:
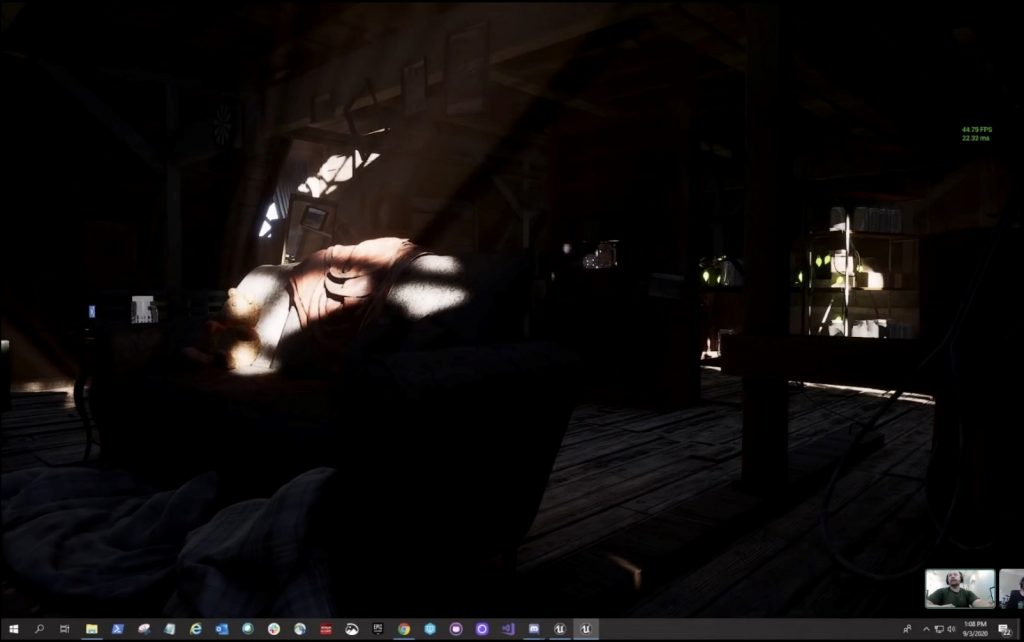
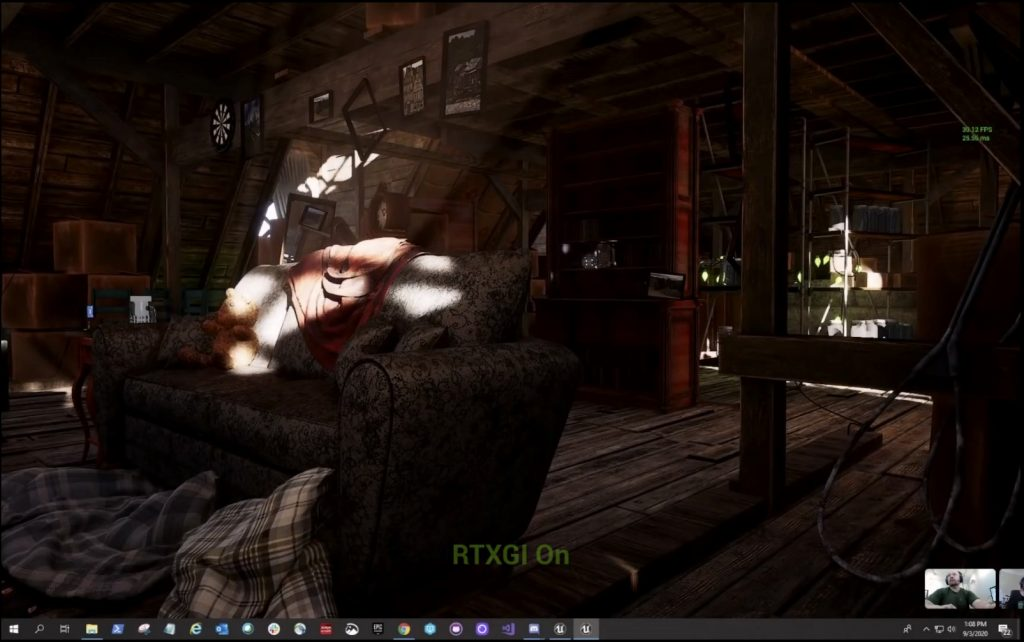
这是一个可以在 Unreal Engine 游戏引擎里打开的全动态光线追踪场景,可供所有人下载,场景在 UE 的视口里以全屏方式渲染,分辨率是 1920x1080。
上图是关闭 RTXGI,下图是打开 RTXGI,其中关闭 RTXGI 的时候,场景里已经应用了光线追踪阴影、光线追踪遮蔽、光线追踪反射、光线追踪半透明等光线追踪特效。
从图中的渲染时间可以看出,开关 RTXGI 的渲染时间区别也就是 2 毫秒左右,相当于 10% 的性能影响,这在游戏中是可以接受的程度。如果保持同样的 RTXGI 设定参数的话,其开销值基本上是固定的,这也是 RTXGI 的特点之一。
也许有人会说,帧率只有 40 fps 左右,似乎不是很爽吧。不急,前面我们提到的 DLSS 大杀器要出场了:
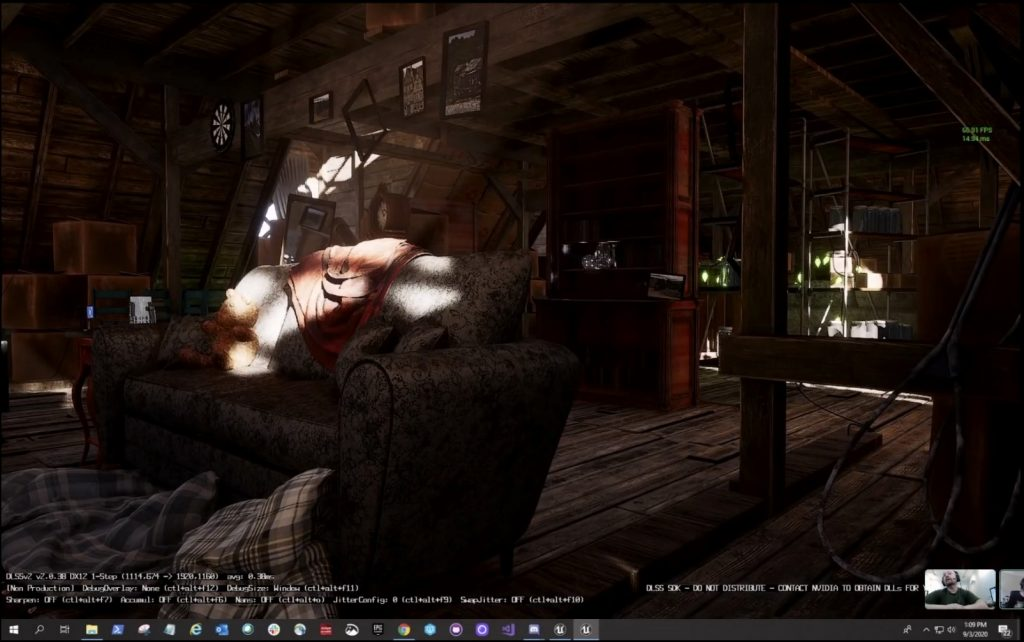
DLSS 2.0 开启后,帧率迅速提升到了 65 fps 的水平,可以看出,RTXGI 让全局照明开销降低到了可用的程度,而 DLSS 2.0 让 RTXGI 的可用性提升了一个档次。
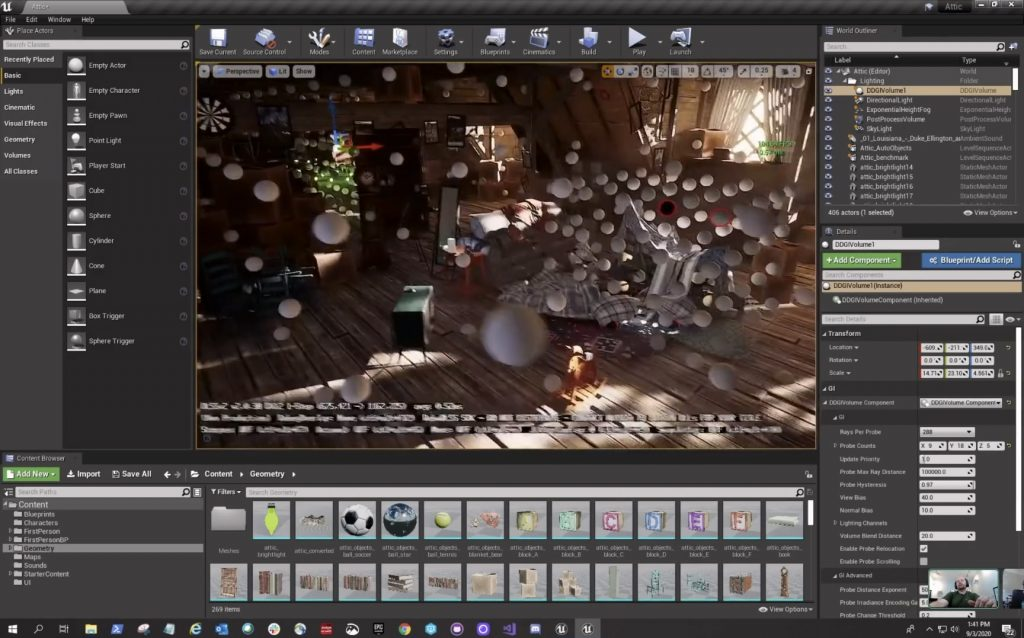
RTXGI 能达到如此高的性能可用性,原因是它的取巧方式:在场景里布置大量的探测球(见上图的白色小球),这些探测球向场景发射射线,获得的距离值和辐射度值被保存起来,然后和标准的光线追踪混合,获得探测球对应位置的亮度值。
和 Path Tracing 每条射线十数次反弹,每次反弹又发射出大量随机方向的射线相比,RTXGI 的性能开销显著降低,而且不会有噪点,常见的漏光问题也基本可以控制得非常好。
类似的渲染方式以往也应用于软件光线追踪里,但是受制于性能,只能使用较低“分辨率”来部署探测球或者保存探测球样本值,如今有了 RT Core 后,可以更大规模地部署探测球获得更多的样本值——意味着更好的渲染结果。
Richard Cowgill 没有透露演示使用的显卡,不过 NVIDIA 在 RTX3000 媒体技术会上公布了一些信息:
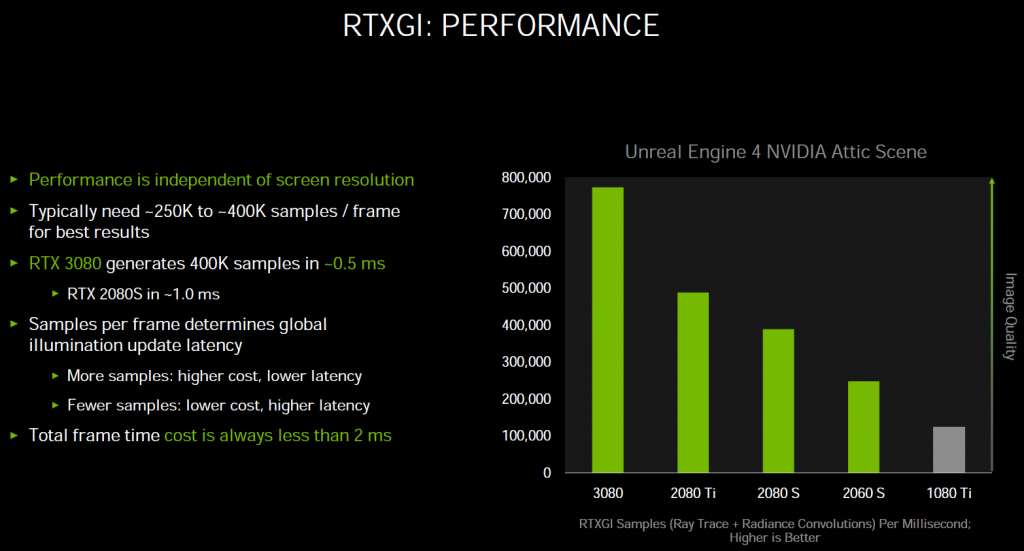
正如你所看到的,RTX 3080 可以在 0.5 毫秒内完成对 40 万次 RTXGI 取样,RTX 2080 Ti 是 1.0ms,RTX 2060 是每毫秒大约 27 万左右。在场景中的探测球数量固定的情况下,RTXGI 的开销基本保持不变,具体开销依赖于当前视口里有多少个探测球被启用(或者说取样规模),因为不管分辨率怎么变化,游戏中的几何体包括探测球规模理论上都不会发生变化。
RTXGI 已经在 Unreal Engine 4.25 上提供,目前需要透过 NVIDIA 开发者网页递交申请,NVIDIAI 的 NvRTX github 也会很快提供下载(也许本文发表的时候你已经可以透过 git 克隆下来了)。
总结
相较于两年前图灵架构带来的革命性特性创新,安培在架构上的演进更像是对强者的全面补强,每个 SM 两倍的浮点性能、更大更灵活的缓存、全面提升的 RT Core 和更追求效率的 Tensor Core、更高带宽的 G6X 内存技术,让 GA10X 在游戏方面实现了前所未有的性能提升。
由于引入大量的新特性,相关新技术的拓展基本上就完全落在 NVIDIA 自己身上,所幸的是,NVIDIA 与各个游戏开发商有密切的合作关系,凭借当初各个院校投放大量资源推动 CUDA,现在在通用计算特别是人工智能领域结出了累累硕果。
图灵架构是首次将硬件光线追踪和硬件 AI 加速集成到了 GPU 里,其中光线追踪是主调,AI 是助推剂,这两个特性在 GA10X 里得到了显著的增强,伴随它们的 DLSS 2.1 和 RTXGI 堪称 RTX 在游戏图形领域目前为止最响亮的合奏曲。
特别是 DLSS,它表现出来的潜力远超出我当初对它的期望,假如有 DLSS 3.0 的话,不敢想象会发展成什么样子。
RTX IO 是另一个值得期待的技术,特别是像 UE5 演示,整个场景有数十亿三角形,每个画面至少包含 3300 万个多边形,如此复杂的场景对存储系统一定会带来前所未有的压力,RTX IO 问世可以说是正逢其时。
安培的 RTX IO 完全采用 SM 进行解压运算,这方面具体表现如何值得期待,也许以后当游戏数据打包格式统一后,未来 GPU 的 RTX IO 还将会引入硬件解压缩单元也不定。
相当于三维渲染和计算方面的快速,NVIDIA 在 NVDEC 新增的 AV1 解码支持也是一个不错的功能,不过这个特性主要有 IT 领域的公司推动,在广播采编领域方面欠缺支持。
某种程度上,这波的视频能力进步略有不足,索尼和 EOS R5/R6 系列的 HEVC 视频采用了 422 采样格式,这方面 NVIDIA 并未提供相应支持,而 Intel 的下一代 CPU 则提供了,当然,这个特性的用户群比较少,对游戏玩家没任何影响。
最后,我还是如以往一样,希望 NVIDIA 在软件开发方面继续加大投入,特别是 DLSS,这个功能不管是什么层面的玩家和三维内容创作用家都能获益。
请登录以参与评论
现在登录